MLOps on GCP - Part 1: Deploy a Vertex AI Training Pipeline for scikit-learn models
By Simon Löw |
In this multi-part series we will build a full MLOps pipeline in GCP, including: Training and Deployment Pipelines, CI/CD pipelines, Feature Store, …
Part I will show you how to build a custom VertexAI training pipeline. By the end of this post you will know:
- How to deploy a Vertex AI pipeline
- How to write Kubeflow components and pass parameters and artifacts between them
- How to train and deploy custom scikit-learn models
- How to use pre-build
google_cloud_pipeline_componentswith your custom model, saving you from writing a lot of boilerplate code yourself
The Pipeline
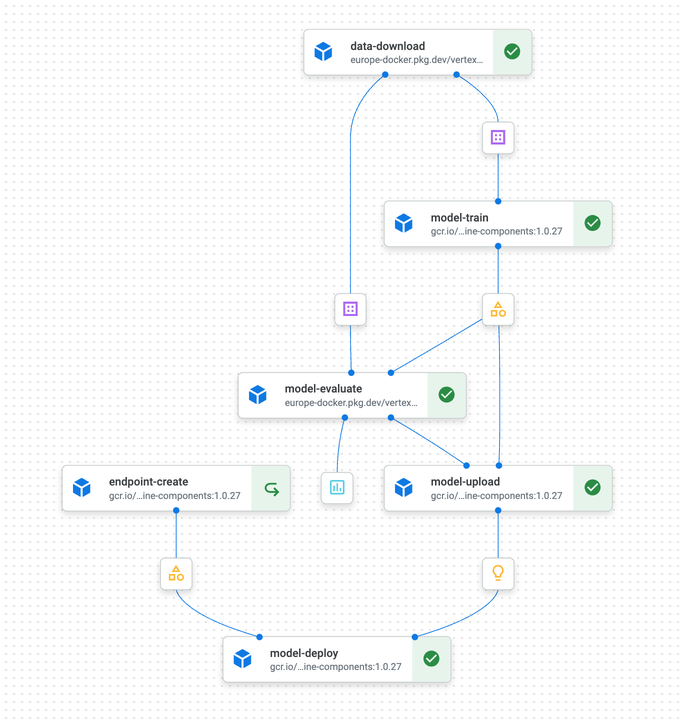
We will build and deploy the following training pipeline:
- Preprocessing (
data-download): Load the dataset from GCS and transform it into training and test set - Training (
model-train): Train a scikit-learn model to predict flight delays. We will use a custom training step here. - Creating a Model Endpoint (
endpoint-create): Create a Vertex AI model endpoint we can deploy our model to. We will use pre-build Kubeflow container components from thegoogle_cloud_pipeline_componentslibrary, which saves us from writing a lot of boilerplate code. - Deploying the model to the endpoint (
model-uploadandmodel-deploy): Upload the model to the Vertex AI model registry and then deploy it to the endpoint, using thegoogle_cloud_pipeline_componentslibrary.
The Dataset
We will predict arrival delays for flights across the US use the Carrier On-Time Performance Dataset from the US Bureau of Transportation. I particularily like that dataset because it gives us plenty of messy real-world data and due to its temporal nature also allows us to simulate some realtime ML with streaming data.
The dataset contains a large number of columns we will explore in a later step of the tutorial, the columns of interest for now are:
- DepDelay: Departure delay in minutes. This will be our main feature to predict arrival delay.
- TaxiOut: The time elapsed between departure from the origin airport gate and wheels off.
- Distance: The flight distance
- Cancelled and Diverted: Did the flight get cancelled or diverted? For now we will exclude those flights.
- ArrDelay: Arrival delay in minutes. This is our prediction target.
I’ve created a script for download the data, extracting it, and uploading it to our GCS bucket. It’s straight forward and can be found on GitHub.
GCP Setup
Before we can start digging into the details we need to setup our GCP project. You can do that using the GCP console or use the CLI tools within Cloud Shell.
- Create a new project (or use one of your existing projects if you like) and enable the Vertex AI API:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
--project=${PROJECT_ID}
- Create a bucket for holding the training artifacts (datasets, models), within your preferred geo region. The region for the bucket doesn’t matter as long as you use the same region for every step within the tutorial. If your bucket is in a different location than your training job, you might be charged for the network traffic:
gcloud storage buckets create gs://training_data_${PROJECT_ID} \
--project=${PROJECT_ID} \
--location="europe-west1"
- Setup a service account for running our pipeline job and give it permissions to access the bucket as well as docker images in GCR:
gcloud iam service-accounts create vertex-ai-service-account \
--description="VertexAI Service Account" \
--display-name="vertex-ai-service-account" \
--project=${PROJECT_ID}
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:vertex-ai-service-account@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:vertex-ai-service-account@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.objectViewer"
gcloud iam service-accounts add-iam-policy-binding \
vertex-ai-service-account@${PROJECT_ID}.iam.gserviceaccount.com \
--member="user:${USER_NAME}" \
--role="roles/iam.serviceAccountUser"
gsutil iam ch \
serviceAccount:vertex-ai-service-account@${PROJECT_ID}.iam.gserviceaccount.com:roles/storage.objectCreator,objectViewer,objectAdmin \
gs://training_data_${PROJECT_ID}
Training Pipeline
No that we have our GCP project in place. Let’s start defining our training pipeline. We will use the Kubeflow SDK to define our whole pipeline in Python. You can find all the code on GitHub.
Preprocessing Step
Let’s start with our first step in the pipeline. There are many ways to define a Kubeflow pipeline component, but the easiest is to use a regular python function. We use the @component decorator to mark it as a pipeline component and specify a docker image to use for the step.
from kfp.v2.dsl import (
Dataset,
Output,
component,
)
@component(
base_image="europe-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest",
)
def data_download(
data_url: str,
split_date: str,
dataset_train: Output[Dataset],
dataset_test: Output[Dataset],
):
import pandas as pd
import logging
logging.warn("Import file:", data_url)
data = pd.read_csv(data_url)
cancelled = (data["Cancelled"] > 0) | (data["Diverted"] > 0)
completed_flights = data[~cancelled]
training_data = completed_flights[["DepDelay", "TaxiOut", "Distance"]]
# Consider flights that arrive more than 15 min late as delayed
training_data["target"] = completed_flights["ArrDelay"] > 15
test_data = training_data[completed_flights["FlightDate"] >= split_date]
training_data = training_data[completed_flights["FlightDate"] < split_date]
training_data.to_csv(dataset_train.path, index=False)
test_data.to_csv(dataset_test.path, index=False)
We use the europe-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest Docker image, since it contains all the scikit-learn dependencies we will need and I’m based in Europe. But you can find all the available images in the GCP Documentation and pick the one that suits your dependecies and geo location. We can also specify python packages as a dependency using the @component(), but I generally don’t recommend it, since it can cause reproducibility issues and can be slow, since dependencies need to be installed before each run.
Defining a pipeline component is not much different from a regular python function, there are however two key differences:
All your dependencies need to imported within the function. When the pipeline is deployed your python function is extract and run within the container. All imports that happen outside of the function are not available during execution.
Pipeline Artifacts (e.g. Dataset, Models, ..) are handled through special function parameters. Those function parameters need to have a type declaration marking them as input (Input[X]) or output (Output[X]). For the preprocessing step we only use outputs to store our training and test set. Artifacts aren’t passed by value, but instead stored as files (on GCS). So to write out our data sets we need to store them in the given location Output.path.
Training Step
from kfp.v2.dsl import (
Artifact,
Dataset,
Input,
Output,
component,
)
@component(
base_image="europe-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest",
)
def model_train(
dataset: Input[Dataset],
model: Output[Artifact],
):
import pandas as pd
import pickle
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
data = pd.read_csv(dataset.path)
X = data.drop(columns=["target"])
y = data["target"]
model_pipeline = Pipeline(
[
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler()),
("clf", LogisticRegression(random_state=42)),
]
)
model_pipeline.fit(X, y)
model.metadata["framework"] = "scikit-learn"
model.metadata["containerSpec"] = {
"imageUri": "europe-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest"
}
file_name = model.path + "/model.pkl"
import pathlib
pathlib.Path(model.path).mkdir()
with open(file_name, "wb") as file:
pickle.dump(model_pipeline, file)
Defining the training step is quite similar to the preprocessing. As before we annotate the function with @component and import all our dependencies within the function scope.
We now define the input as Input[Dataset] so that we can pass in the training dataset from the previous step. As before this doesn’t pass in the dataset itself, but provides us with a url to load the dataset within our training step.
The only output is the trained model. Usually we would define it as Output[Model], but that doesn’t work with the google_cloud_pipeline_components library, which expects an output of the type UnmanagedContainerModel. Unfortunately, kubeflow pipelines don’t support custom artifact types at this point, so we have to declare it as a generic Output[Artifact]. But adding containerSpec as custom metadata does the trick for us:
model.metadata['containerSpec'] = {
'imageUri': "europe-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest"
}
The training itself is done in the usual scikit learn way. We define a Pipeline and call fit() to train it. We than export the model as a pickle file. Vertex AI is able to read those pickle files directly and can deploy the model for us. No manual prediction code needed!
Evaluation Step
from kfp.v2.dsl import (
Dataset,
Input,
Model,
Output,
ClassificationMetrics,
component,
)
@component(
base_image="europe-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest",
)
def model_evaluate(
test_set: Input[Dataset],
model: Input[Model],
metrics: Output[ClassificationMetrics],
):
import pandas as pd
import pickle
from sklearn.metrics import roc_curve, confusion_matrix, accuracy_score
data = pd.read_csv(test_set.path)[:1000]
file_name = model.path + "/model.pkl"
with open(file_name, "rb") as file:
model_pipeline = pickle.load(file)
X = data.drop(columns=["target"])
y = data.target
y_pred = model_pipeline.predict(X)
y_scores = model_pipeline.predict_proba(X)[:, 1]
fpr, tpr, thresholds = roc_curve(y_true=y, y_score=y_scores, pos_label=True)
metrics.log_roc_curve(fpr.tolist(), tpr.tolist(), thresholds.tolist())
metrics.log_confusion_matrix(
["False", "True"],
confusion_matrix(y, y_pred).tolist(),
)
The evaluation step takes the model and the test set and calculations several evaluation metrics, as you can see in the code above we are able to export metrics like ROC curves or confusion matrices and will be able to see the output in the google console.
Deployment Step
Now let’s finally deploy the model. To simplify the process we can use predefined components from the google_cloud_pipeline_components library.
model_upload_op = ModelUploadOp(
project=PROJECT_ID,
location=REGION,
display_name="flight-delay-model",
unmanaged_container_model=model_train_op.outputs["model"],
)
endpoint_create_op = EndpointCreateOp(
project=PROJECT_ID,
location=REGION,
display_name="flight-delay-endpoint",
)
ModelDeployOp(
endpoint=endpoint_create_op.outputs["endpoint"],
model=model_upload_op.outputs["model"],
deployed_model_display_name="flight-delay-model",
dedicated_resources_machine_type="n1-standard-4",
dedicated_resources_min_replica_count=1,
dedicated_resources_max_replica_count=1,
)
Putting everything together
Now that we have all the pipeline components we can put them together in the final pipeline and compile the pipeline definition into a JSON file:
from kfp.v2.dsl import pipeline
from kfp.v2 import compiler
from google_cloud_pipeline_components.v1.endpoint import EndpointCreateOp, ModelDeployOp
from google_cloud_pipeline_components.v1.model import ModelUploadOp
@pipeline(name="gcp-mlops-v0", pipeline_root=pipeline_root_path)
def pipeline(
training_data_url: str = f"gs://{BUCKET}/data/2021/2012-01.csv",
test_split_date: str = "2021-12-20",
):
data_op = data_download(
data_url=training_data_url,
split_date=test_split_date
)
from google_cloud_pipeline_components.experimental.custom_job.utils import (
create_custom_training_job_op_from_component,
)
custom_job_distributed_training_op = create_custom_training_job_op_from_component(
model_train, replica_count=1
)
model_train_op = custom_job_distributed_training_op(
dataset=data_op.outputs["dataset_train"],
project=PROJECT_ID,
location=REGION,
)
model_evaluate_op = model_evaluate(
test_set=data_op.outputs["dataset_test"],
model=model_train_op.outputs["model"],
)
model_upload_op = ModelUploadOp(
project=PROJECT_ID,
location=REGION,
display_name="flight-delay-model",
unmanaged_container_model=model_train_op.outputs["model"],
).after(model_evaluate_op)
endpoint_create_op = EndpointCreateOp(
project=PROJECT_ID,
location=REGION,
display_name="flight-delay-endpoint",
)
ModelDeployOp(
endpoint=endpoint_create_op.outputs["endpoint"],
model=model_upload_op.outputs["model"],
deployed_model_display_name="flight-delay-model",
dedicated_resources_machine_type="n1-standard-4",
dedicated_resources_min_replica_count=1,
dedicated_resources_max_replica_count=1,
)
compiler.Compiler().compile(
pipeline_func=pipeline, package_path="gcp-mlops-v0.json"
)
Now we can deploy and run our pipeline. Go to the Vertex AI Pipeline page in the Console to follow the process of the pipeline
from google.cloud import aiplatform as aip
aip.init(project=PROJECT_ID, staging_bucket=BUCKET, location=REGION)
job = aip.PipelineJob(
display_name="gcp-mlops-v0",
template_path="gcp-mlops-v0.json",
pipeline_root=pipeline_root_path,
)
job.run(service_account=SERVICE_ACCOUNT)
Viewing the Pipeline and Artifacts
After succesfully running the pipeline, we can now view the results in the GCP console. The Vertex AI Pipeline tab shows all the step in our pipeline, including all the artifacts we created. If we run the pipeline multiple times it keeps track of all the different versions of the artifacts and even tracks the data lineage across multiple steps. By clicking on the metrics artifact, we can also review all the metrics we exported during our model-evaluation step.
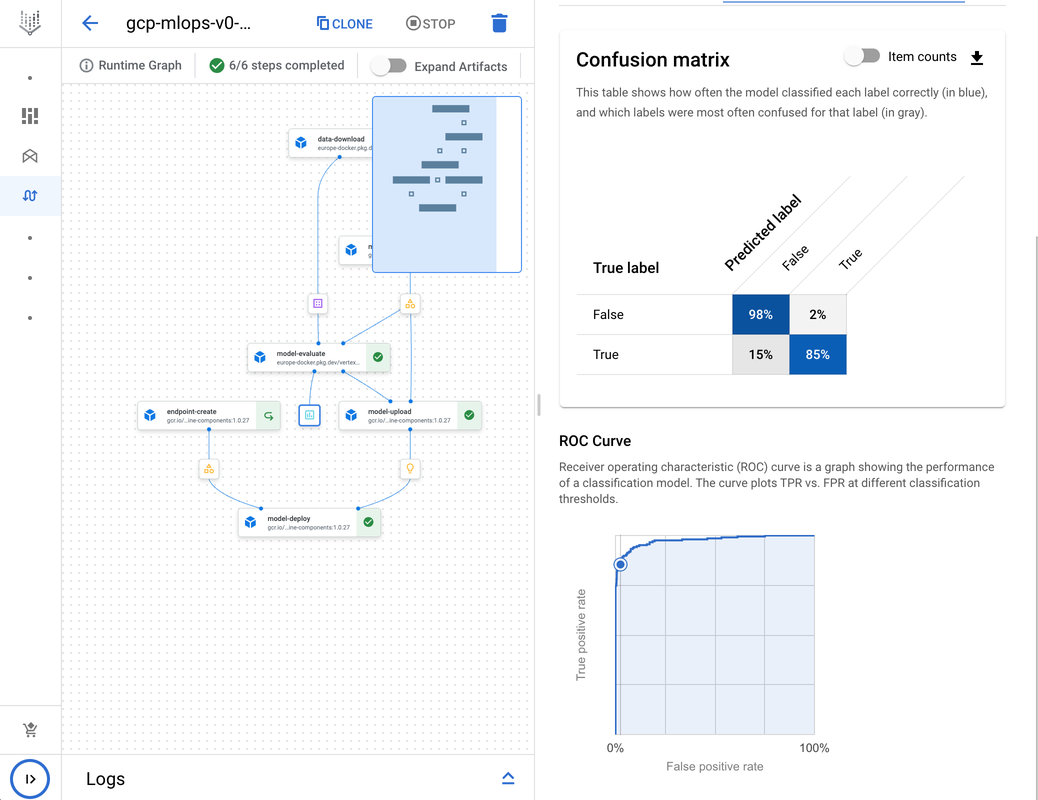
Using the Vertex AI Endpoint for Prediction
We can now use our endpoint to retrieve some new predictions. You can find the endpoint id clicking on the endpoint artifact in the pipeline view:
from google.cloud import aiplatform as aip
aip.init(project=PROJECT_ID, location=REGION)
endpoint = aip.Endpoint(ENDPOINT_ID)
prediction = endpoint.predict(instances=[[-4.0, 16.0, 153.0]])
Summary
We now finished the first step towards a fully automated MLOps pipeline and successfully deployed our model training pipeline. If new data arrives we can just rerun our pipeline to get a new model. GCP takes care of all the housekeeping around it. It will track all the artfacts and differnt model version for you.
In Part 2 we will add the Vertex AI Feature Store to our pipeline. This enables us to handle features more consistently across training and model serving and will greatly reduce the risk of training-serving-skew.
Like the post? Share it!

Simon Löw
Machine Learning Engineer - Freelancer
I'm an ML Engineer freelancer focusing on building end-to-end machine learning solutions, including the MLOps infrastructure and data pipelines.
I've worked with various startups and scale-ups, including Klarna and Depict, building automated ML platforms, credit risk models, recommender systems, and the surrounding cloud infrastructure.
On this blog, I'm sharing my experience building real-world end-to-end ML solutions.
Follow me on LinkedIn