MLOps on GCP - Part 2: Using the Vertex AI Feature Store with DataFlow and Apache Beam
By Simon Löw |
In Part 1 of the MLOps on GCP series we implemented our training pipeline using Vertex AI Pipelines. This is the first step towards reproducibility and will allow us to re-run the exact same training steps whenever we detect model drift or receive new data. In this part we will focus on reproducible feature transformations and introduce a Feature Store to our pipeline. The Feature Store gives us a central place to store all our features during training and serving and helps to avoid Training-Serving-Skew.
In this post you will learn:
- What is a Feature Store and why do we need it in our MLOps pipeline
- How to use the GCP Vertex AI Feature Store with batch data
- How to build reproducible feature transformation pipelines with Apache Beam and GCP Dataflow
- How to train a Vertex AI model using data from the Feature Store
- How to retrieve features in realtime during model prediction
Why should we use a Feature Store?
One of the biggest problems in production machine learning is training-serving-skew. I’ve experienced it myself countless times how minor differences in the training and production environment can drastically change model results. But all too often subtle differences in the data get unnoticed and can impact model performance for a long time until they are finally detected.
The main sources of training-serving-skew are differences in the data transformations between our training and production environment. While simple feature transformations can be handled within the model itself, complex transformations require external pre-processing logic. This logic is often implemented in multiple places, using different programing languages and frameworks. It’s for example not uncommon to implement batch feature transformations in Python during the model training process, but then reimplement the logic in the JavaScript code that calls the final model in realtime. Even with great care, different code path can lead to differences in the data transformations and impact model performance.
A Feature Store gives us a central place to store features and allows us to retrieve them both during batch training and real-time serving. The Feature Store also keeps track of the timestamp of different feature values and ensures we always join the ones values for the given timestamp. This is vital for generating training datasets, where we want to avoid leaking future information into our dataset. Combining a Feature Store with centralized feature pipelines ensures that we peforme feature transformations consistently and greatly reduces the risk of training-serving-skew.
In our case, we will calculate a moving average of flight delays for each airport. This is a prime example of the use of a feature store:
- The moving average requires knowledge about previous flights. During real-time predictions, we only have information about our own flight. Thus we need a data pipeline and a feature store to precalculate the average delays and store the results for fast real-time retrieval.
- During training we need to make sure that we match the right moving average with the right flight. During realtime prediction we don’t know about future flight delays, so we should only use information that happened before our flight. A feature store can help us to make time-correct joins between our moving average feature and flight features.
Architecture
We will implement a DataFlow pipeline to calculate moving average features for our model. One of the key benefits of DataFlow (and Apache Beam) is that it can handle both batch and streaming data. We can implement our moving average logic once and use it in batch mode to generate the training data. Later on, we can run the same logic in a streaming pipeline to update our average flight delay feature in real-time.

Anatomy of the Vertex AI Feature Store
Let’s now have a look at the architecture of our Feature Store. The Vertex AI Feature Store is based on three hierarchical entities:
- Feature Store: Place to store multiple entities / features
- Entity: An object that can hold features. Can be modeled after a real entity or a virtual/logic entity
- Feature: The actual feature
For our use case we create one new feature store to hold all our entities and define the following two entities:
- Flight: Represents a single flight and maps 1-1 to one row in the input CSV. This entity contains all the features we used in the first part of this tutorial.
- Airport: Represents the origin airport. We define a new
average_departure_delayfeature, which represents the average delays for that origin airport over the last 4 hours. We assume that this is a good proxy for the congestion and general delays at the origin airport and a strong indicator if our flight is delayed as well.
Each entity also needs to have a unique id and an associated timestamp. For the flight, we use a combination of the airline id and the flight number as the unique id, for the airport we can use the unique airport id. This will allow us to connect the airport entity to the flight entity later.
Setup
Additionally to the setup from Part 1 we need to:
- Enable the dataflow api:
gcloud services enable dataflow.googleapis.com \
--project=${PROJECT_ID}
- Make sure our service account has BigQuery permissions. This is needed since the feature store will temporarily store our training dataset in BigQuery:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:vertex-ai-service-account@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/bigquery.dataOwner"
Implementing the Feature Store and Data Pipelines
Setup the Vertex AI Feature Store
Let’s start with setting up the Feature Store and creating our entities and features as described above. You can find the full code on GitHub.
We first create a new feature store called flight_delays, which will hold all our entities and features. We then create our flight and airport entities and add features to them. For each feature we need to define the type and add a meaningful description to them:
from google.cloud import aiplatform as aip
from .config import PROJECT_ID, BUCKET, REGION
aip.init(project=PROJECT_ID, staging_bucket=BUCKET, location=REGION)
flight_delays_feature_store = aip.Featurestore.create(
"flight_delays", online_store_fixed_node_count=1
)
airport_entity_type = flight_delays_feature_store.create_entity_type(
entity_type_id="airport",
description="Airport entity",
)
airport_entity_type.create_feature(
feature_id="average_departure_delay",
value_type="DOUBLE",
description="Average departure delay for that airport, calculated every 4h with 1h rolling window",
)
# [...]
Create Batch Features
To transform our raw data into features we will use Apache Beam on Dataflow. This allows to us use the same feature transformation code for both batch and real-time (see Architecture diagram above). We will read the raw CSV file from GCS and write output two AVRO files back to GCS - one for the flight entities and one for the airport entities.
Let’s define our entity types as NamedTuple first. We can use them within our Beam pipeline to pass around structured data as well as to generate AVRO schemas for our output files.
class Flight(NamedTuple):
timestamp: Optional[datetime]
flight_number: str
origin_airport_id: str
is_cancelled: bool
departure_delay_minutes: float
arrival_delay_minutes: float
taxi_out_minutes: float
distance_miles: float
class AirportFeatures(NamedTuple):
timestamp: Optional[datetime]
origin_airport_id: str
average_departure_delay: float
I added a helper function named_tuple_to_avro_fields() to automatically generate AVRO schemas out of our type definitions. The code can be found on GitHub:
flight_avro_schema = {
"namespace": "flight_delay_prediction",
"type": "record",
"name": "Flight",
"fields": named_tuple_to_avro_fields(Flight),
}
# [...] same for the airports, see GitHub for the full code
We can now define our Apache Beam pipeline.
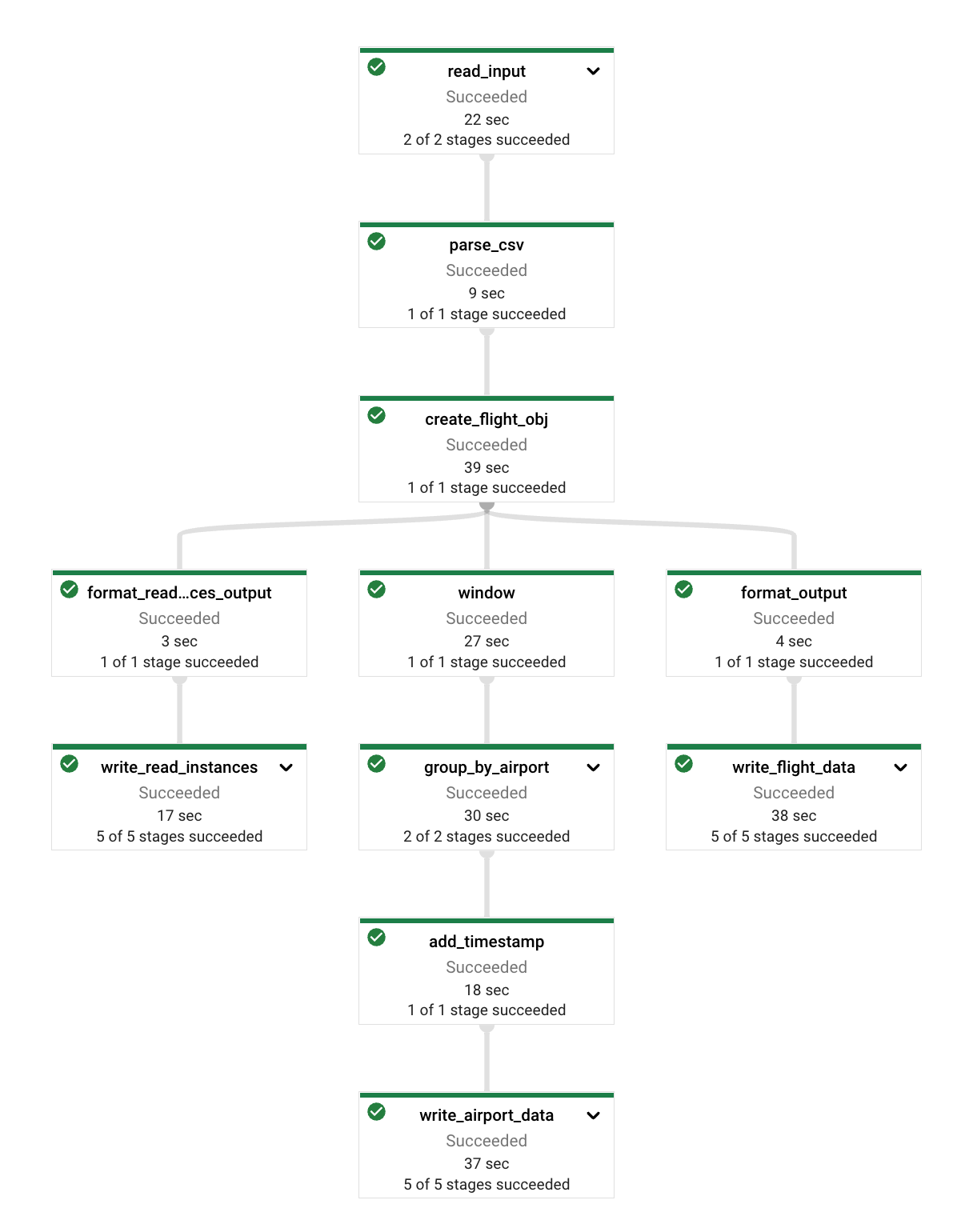
We will first ingest and parse the CSV file into Flight objects. We then split up the pipeline into three separate paths:
- Flight Entities: These are pretty much the static features we used in part 1 of the tutorial. We filter out the relevant fields from the input and assign the correct timestamp to each record. The timestamp is essential since we will use it later to join the flight features with the airport features at the time of the flight. We then write out an AVRO file with the data.
- Airport Entities: The airport features represent the state of the airport at a specific timestamp. For simplicity the only feature we will calculate here is a moving average of flight delays for each origin airport. To calculate the average delays we need to add a
SlidingWindowand group ourFlightentities byorigin_airport_id. We can then aggregate delays for each sliding window and create aAirportobject. Note that we have to assign the end of the window as thetimestampfor each entity, otherwise we would use future information when we join theAirportentities with theFlightentities later. - Read instances: To generate a training dataset from the Feature Store, we need to provide a file that lists all the flights we are interested in. This file should contain the flight id, airport id, and timestamp for each flight. In a real-world scenario you would probably have a BigQuery table listing all the flights, for simplicity we will just generate a CSV file in GCS that we will hand to the feature store later.
flights = (
pipeline
| "read_input" >> beam.io.ReadFromText(known_args.input)
| "parse_csv" >> beam.Map(parse_csv)
| "create_flight_obj" >> beam.FlatMap(parse_line).with_output_types(Flight)
)
# Create airport data
(
flights
| "window"
>> beam.WindowInto(
beam.window.SlidingWindows(4 * 60 * 60, 60 * 60)
) # 4h time windows, every 60min
| "group_by_airport"
>> beam.GroupBy("origin_airport_id").aggregate_field(
"departure_delay_minutes",
beam.combiners.MeanCombineFn(),
"average_departure_delay",
)
| "add_timestamp" >> beam.ParDo(BuildTimestampedRecordFn())
| "write_airport_data"
>> beam.io.WriteToAvro(
known_args.output_airports, schema=airport_avro_schema
)
)
# Create flight data
(
flights
| "format_output" >> beam.ParDo(BuildTimestampedFlightRecordFn())
| "write_flight_data"
>> beam.io.WriteToAvro(known_args.output_flights, schema=flight_avro_schema)
)
# Create read_instances.csv to retrieve training data from the feature store
(
flights
| "format_read_instances_output"
>> beam.Map(
lambda flight: f"{flight.flight_number},{flight.origin_airport_id},{flight.timestamp.isoformat('T') + 'Z'}"
)
| "write_read_instances"
>> beam.io.WriteToText(
known_args.output_read_instances,
file_name_suffix=".csv",
num_shards=1,
header="flight,airport,timestamp",
)
)
You can find the full code on GitHub.
We can now run Dataflow pipeline. This will take a few minutes and will generate two AVRO outputs in GCS:
python -m venv .venv
source .venv/bin/activate
pip install -e .
python ./main.py \
--input=gs://${BUCKET}/data/2021/2021-12.csv \
--output-flights=gs://${BUCKET}/features/flight_features/ \
--output-airports=gs://${BUCKET}/features/airport_features/ \
--output-read-instances=gs://${BUCKET}/features/read_instances/ \
--runner=DataflowRunner \
--project=${PROJECT_ID} \
--region=europe-west1 \
--staging_location=gs://${BUCKET}/beam_staging \
--temp_location=gs://${BUCKET}/beam_tmp \
--job_name=flight-batch-features \
--setup_file ./setup.py
Ingest batch features
We can now ingest the AVRO files into out Feature Store (Full code on GitHub):
airport_entity_type.ingest_from_gcs(
feature_ids=["average_departure_delay"],
feature_time="timestamp",
gcs_source_uris=f"gs://{BUCKET}/features/airport_features/*",
gcs_source_type="avro",
entity_id_field="origin_airport_id"
)
Train the model using data from the Feature Store
We now successfully ran our feature pipelines, generated all the relevant features, and stored them in the Vertex AI Feature Store. Let’s now update our pipeline from Part 1 to ingest data from the Feature Store:
- Load the
read_instances.csvwe created in our DataFlow pipeline. This file contains a timestamp, flight id, and airport id for each of our training samples. The feature store will use that file to join all flight features with all airport features using only information that was available at the given timestamp. - Create a batch dataset using
Featurestore.batch_serve_to_df(). This will create a temporary table in BigQuery and then load our dataset into a pandasDataFrame. - Preprocess the dataset as before. We drop all unnecessary columns, define our prediction target, and split the dataset into training and test set.
@component(
base_image="python:3.9",
packages_to_install=[
"google-cloud-aiplatform==1.20.0", "pandas", "fsspec",
"gcsfs", "google-cloud-bigquery-storage", "pyarrow"
],
)
def data_download(
project: str,
location: str,
feature_store: str,
data_url: str,
split_date: str,
dataset_train: Output[Dataset],
dataset_test: Output[Dataset],
):
import pandas as pd
from google.cloud import aiplatform as aip
aip.init(project=project, location=location)
flight_delays_feature_store = aip.Featurestore(featurestore_name=feature_store)
# Load read instances from GCS file
read_instances = pd.read_csv(data_url)
# Make sure all columns have the type batch_serve_to_df expects
read_instances["flight"] = read_instances["flight"].astype(str)
read_instances["airport"] = read_instances["airport"].astype(str)
read_instances["timestamp"] = pd.to_datetime(read_instances["timestamp"])
# Read features into a dataframe
data : pd.DataFrame = flight_delays_feature_store.batch_serve_to_df(
serving_feature_ids={
"flight": ["*"],
"airport": ["*"],
},
read_instances_df=read_instances,
)
# [...] Preprocessing data as before
You can find the full code on GitHub. Note that I’m using the regular python:3.9 and installing the google-cloud-aiplatform as a dependency since the google provided images didn’t include the correct version. While I generally recommend building your own docker images and storing them in ECR to avoid reproducibility issues, it’s ok to do it like that here since we merely load the data from the feature store.
The second part to note is that batch_serve_to_df() is very peculiar about the read_instances_df, so we have to make sure all our DataFrame columns have the right type.
We can now run our training pipeline as before. Which will load the data from the Feature Store, train a new model, and deploys it to a model endpoint.
Fetching features in realtime
We are now ready to run our model in real-time. We will provide flight features directly in the model request while fetching airport features from the feature store. This is a common scenario:
- Flight features are known to the system that makes the request and are still changing during the request. E.g. the current flight delay changes every minute until the plane finally takes off. For the real-time prediction case, it doesn’t make sense to store the flight information in the feature store and to update it every time a value changes. This can add a lot of additional cost and latency. We will provide the flight features in the request instead and then periodically import historic flight data into our feature store to make it available for batch training. (This can be done for example with a Airflow DAG / Cloud Composer.) Note that this is a potential source of training serving skew, but since we only use static flight information without any transformation the risk is relatively small.
- Airport features on the other hand require our feature pipeline and aren’t known to the requester. The moving average feature needs access to all previous flights, is costly to calculate, and carries a high risk of training-serving-skew. Here it makes sense to run a streaming pipeline to continuously update the airport features in the feature store and retrieve the value in real-time based on the airport id.
You can see an example request below. In production, this would most likely be implemented as a REST endpoint using for example Cloud Functions, but for simplicity, we just run a local script here:
from google.cloud import aiplatform as aip
# This would usually come from a REST request
inputs = {
"distance_miles": 481.0,
"departure_delay_minutes": -6.0,
"taxi_out_minutes": 13.0,
"airport_id": "13851",
}
aip.init(project=PROJECT_ID, location=REGION)
flight_delays_feature_store = aip.Featurestore(
FEATURE_STORE_ID,
project=PROJECT_ID,
location=REGION,
)
airport_entity_type = flight_delays_feature_store.get_entity_type("airport")
features_df = airport_entity_type.read(
entity_ids=inputs["airport_id"], feature_ids=["average_departure_delay"]
)
print("Airport features", features_df)
endpoint = aip.Endpoint(ENDPOINT_ID)
prediction = endpoint.predict(
instances=[
[
inputs["distance_miles"],
inputs["departure_delay_minutes"],
inputs["taxi_out_minutes"],
features_df["average_departure_delay"].iloc[0],
]
]
)
print("PREDICTION:", prediction)
Summary & Next Steps
We now added a Feature Store and feature processing pipeline to our MLOps architecture. This ensures consistent feature transformations across model deployments and provides reliable feature storage. We can retrieve time-correct information for batch training and low-latency real-time data for prediction while minimizing the risk of training-serving-skew. You can check out the full code for part 2 on GitHub.
For the example setup here we only use Apache Beam and Dataflow in batch mode and then import the features into the feature store. In a real-life scenario, we would also need to deploy a streaming pipeline to continuously calculate the moving average features for each airport. Since Apache Beam supports both batch and streaming pipelines, we can easily reuse our batch feature pipeline to update streaming features in real-time and ensure that transformations are handled consistently in both environments. Stay tuned for the next post to see how the streaming pipeline can be implemented and how to update features in the Feature Store in real-time.
Like the post? Share it!

Simon Löw
Machine Learning Engineer - Freelancer
I'm an ML Engineer freelancer focusing on building end-to-end machine learning solutions, including the MLOps infrastructure and data pipelines.
I've worked with various startups and scale-ups, including Klarna and Depict, building automated ML platforms, credit risk models, recommender systems, and the surrounding cloud infrastructure.
On this blog, I'm sharing my experience building real-world end-to-end ML solutions.
Follow me on LinkedIn