SqueezeNet and MobileNet: Deep learning models for mobile phones
By Simon Löw |
Do you want to use image recognition in your mobile app? To deploy machine learning models to your phone and get fast predictions, the model size is key. SqueezeNet and MobileNet are two network architectures that are well suited for mobile phones and achieve impressive accuracy levels above AlexNet. While the current trend is to make deeper and deeper networks to improve accuracy, SqueezeNet and MobileNet both try to keep the models small and efficient without sacrificing too much accuracy. They both use smart tricks in their architecture that we will investigate in the following. This post will give you an overview over their architecture and summarizes what tricks we can use in our own models to make them more efficient. If you want to apply MobileNet directly to your problem, stay tuned for my next post where I will show you how to use MobileNet together with TensorFlow Lite. What you will learn:
- The idea behind SqueezeNet and fire modules
- Why fully connected layers can be problematic and how max pooling layers can solve the problems
- The idea behind MobileNet and spatial separable convolutions
- The different versions of MobileNet and how to pick the right hyper parameters for your problem
SqueezeNet
SqueezeNet achieves the same accuracy as AlexNet but has 50x less weights. To achieve that SqueezeNet has following key ideas:
- Replace 3x3 filters with 1x1 filters: 1x1 have 9 times fewer parameters.
- Decrease the number of input channels to 3x3 filters: The number of parameters of a convolutional layer depends on the filter size, the number of channels, and the number of filters.
- Downsample late in the network so that convolution layers have large activation maps: This might sound counter intuitive. But since the model should be small, we need to make sure that we get the best possible accuracy out of it. The later we down sample the data (e.g. by using strides >1) the more information are retained for the layers in between, which increases the accuracy.
Fire module
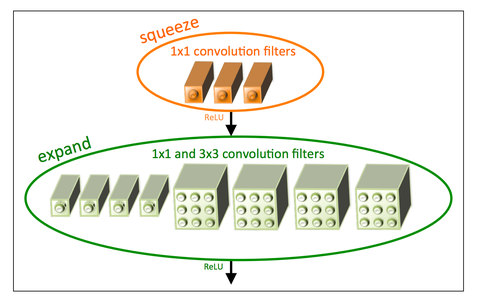
All these ideas are combined into a so called fire module. A fire module is split into two layers, a squeeze layer and an expansion layer. The squeeze layer consists of 1x1 convolutions. If you haven’t seen them before, it might look strange: What a 1x1 convolution essentially does is combining all the channels of the input data into one and thus reduces the number of input channels for the next layer (see Strategy 2 above). The next step is the expansion layer,. Here 1x1 convolutions are mixed with 3x3 convolutions (Strategy 1). The 1x1 convolutions can’t detect spatial structures, but combine the channels of the previous layer in various ways. The 3x3 convolutions detect structures in the image. By combining two different filter sizes the model becomes more expressive and at the same time reduces the number of parameters. The correct padding makes sure that the output of the 1x1 and 3x3 convolutions have the same size and can be stacked.
Architecture
SqueezeNet uses 8 of these fire modules and a single convolutional layer as an input and output layer. What’s remarkable is that the SqueezeNet architecture doesn’t use any fully connected layers. Fully connected layers have a large amount of parameters compared to convolutional layers and are prone to overfitting. SqueezeNet uses global average pooling instead. Global average pooling takes each channel from the previous convolutional layer and builds an average over all values. Max pooling layers don’t have any weights and don’t contribute to the model size. In addition, they tend not to overfit as much as fully connected layers. To make that work, you need to make sure that your last convolutional layer has as many output channels as the number of categories you want to predict. So e.g. if you have a classification problem with 10 categories, you have to make sure that the last convolutional layer uses 10 filters, which leads to an output with 10 channels.
The take away
Fire modules as well as the lack of fully connected layers are great ways to reduce the model size. By applying these techniques SqueezeNet achieves accuracy levels above AlexNet with 50x less weights. Thus the model is well suited for mobile applications. If you want to learn more about SqueezeNet and the ideas behind it, I highly recommend to read the origin paper. While SqueezeNet is an interesting architecture, I recommend MobileNet for most practical applications. So let’s jump right into MobileNet now.
MobileNet
MobileNet follows a little bit different approach and uses depthwise separable convolutions. By that MobileNet is able to outperform SqueezeNet in most cases by having a comparable model size.
Depthwise separable convolutions
Normal convolutional filters work across all input channels. Let’s say you use five 3x3 filter and have 10 input channels, than your convolutional layer has 5x3x3x10 = 450 parameters. Depthwise separable convolutions apply filters to each channel separately and then combines the output channels with a 1x1 convolution. Thus the number of parameters is 5x3x3+10x1x1x5=95 parameters for one depthwise convolution. This leads to a great reduction in parameters, while keeping the accuracy nearly the same.
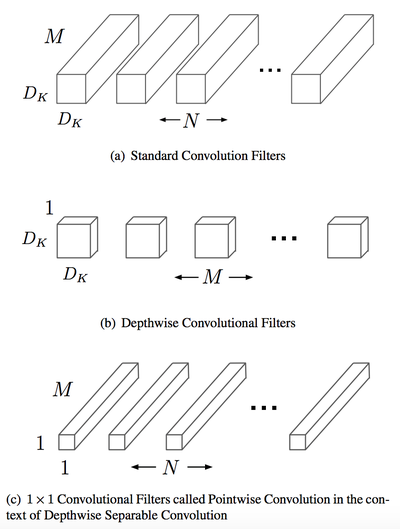
Architecture
The MobileNet architecture uses only depthwise separable convolutions except for the first layer that uses a full convolution. Like SqueezeNet the output of the last convolutional layer is put into a global average pooling layer. But the output of the pooling layer isn’t used directly for classification and is followed by a final fully connected layer. However, since global max pooling is applied first, the final fully connected layer is much smaller compared to classical architectures, where the output of the convolutional layer is used directly in a fully connected layer.
Adaptable architecture: How to pick the right hyper parameters
The nice part about MobileNet is that it has two hyper parameters to adapt the architecture to your needs, α and ρ. α defines the number of input and output channels, while ρ controls the image size. α is defined explicitly between 0 and 1. 1 corresponds to the default number of channels in the convolutions. Other sensible choices are 0.75 and 0.5. Reducing the number of channels reduces the number of weights as well as the computational costs. ρ is set implicitly by changing the size of the input images. Since the number of weights for the convolutional layers depend on the number of channels and filters, this doesn’t reduce the number of weights, but has a huge influence on the number of computations. If you want to increase the prediction speed, but are not too restricted in your model size, it’s better for most cases to reduce the image size instead of the number of channels.
Adapt MobileNet to different problems
The original paper shows how flexible MobileNet is. By choosing the correct hyper parameters you can adapt it perfectly to your use case. Furthermore, MobileNet achieves really good accuracy levels. It outperforms SqueezeNet on ImageNet, with a comparable number of weights, but a fraction of the computational cost. But MobileNet isn’t only good for ImageNet. You can adapt MobileNet to your use case using transfer learning or distillation. The paper shows that MobileNet performs really well under these scenarios. In one of my next posts I will go deeper into MobileNet and show you how to adapt it to your use case or deploy it to a mobile device. I can also recommend to take a look at the experiments in the original paper, to see the different use cases and their performance.
Conclusion
Both SqueezeNet and MobileNet are well suited for mobile phone applications. Fire modules, global average pooling layers and depthwise separable convolutions are great ways to reduce model size and boost prediction speed. So keep them in mind, if you need to create a small and efficient deep learning architecture. For most use cases I recommend to use MobileNet directly instead of inventing your own architecture. By picking different hyper parameters you can adapt the model size and the prediction speed to your needs. If you already have an existing model that you want to use on mobile phones, distillation is a good way to go. Furthermore, you can use transfer learning to adapt MobileNet to your use case. The best part is that Tensorflow provides ready to use models for TensorFlow Lite, which can save you a lot of time. Stay tuned for one of my next posts, where I show you how to use MobileNet with TensorFlow Lite in practice.
Like the post? Share it!

Simon Löw
Machine Learning Engineer - Freelancer
I'm an ML Engineer freelancer focusing on building end-to-end machine learning solutions, including the MLOps infrastructure and data pipelines.
I've worked with various startups and scale-ups, including Klarna and Depict, building automated ML platforms, credit risk models, recommender systems, and the surrounding cloud infrastructure.
On this blog, I'm sharing my experience building real-world end-to-end ML solutions.
Follow me on LinkedIn