Run SageMaker Processing Jobs from Step Functions
By Simon Löw |
SageMaker Processing jobs are a great way to run heavy processing steps in your machine learning pipeline, without the need for setting up an ECS cluster or a Batch job. But integrating them into a Step Functions workflow can be tricky, since there is no direct service integration for processing jobs. In the following I will show you, how you can easily run and monitor SageMaker Processing jobs from Step Functions.
Update
Step Functions now provide full integration for SageMaker Processing Jobs and can controll them directly from the Amazon States Language.
But for most Machine Learning use-cases I nowadays recommend SageMaker Pipelines, which provide a nice Python SDK and fully integrate with other SageMaker services like experiment tracking.
The Concept
To run the processing job from our Step Function, we will implement two Lambda functions:
- The first function will start the processing job and return the job name. All relevant parameters are exposed to the Step Function. So you can implement it once and use it to trigger all kinds of processing jobs, no matter what container and script you use.
- The second function will monitor your processing jobs. Given the job name it returns the the current job status.
In your Step Function you can then trigger the processing job once and periodically check the status until the job either succeeds or fails:
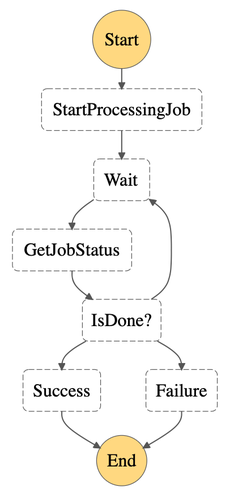
Side note: You could also implement one Lambda function that starts the processing job and waits for the result. But the downsides are, that you pay for your lambda function the whole time the processing job is running and your are subjective to Lambda limits: If your processing job runs more than 15 minutes your Lambda function gets killed and your Step Function workflow fails.
Lambda Function: Starting a SageMaker Processing Job
Let’s jump right into the code and implement the first Lambda function to trigger a processing job.
We use the boto3 API here, since they are preinstalled in the execution environment. You could also use the SageMaker SDK, which makes the code a bit nicer. But we would need to setup our own execution environment. Currently, the SageMaker SDK isn’t officially supported in Lambdas and requires some extra hacks.
The SageMaker SDK provides three different classes Processor, ScriptProcessor and SKLearnProcessor. Under the hood all of them follow the same principle, but use different Docker images for the execution environment. Custom scripts are handled as input in the same way as the training data. That means we can implement all three cases with one Lambda function. Dependent on what Docker image you use and if you specify a script or not, it will behave like one of the three classes above:
import os
import json
import boto3
import time
from typing import Optional
sm = boto3.client('sagemaker')
def get_unique_job_name(base_name: str):
""" Returns a unique job name based on a given base_name
and the current timestamp """
timestamp = time.strftime('%Y%m%d-%H%M%S')
return f'{base_name}-{timestamp}'
def get_file_input(name: str, input_s3_uri: str, output_path: str):
""" Returns the input file configuration
Modify if you need different input method """
return {
'InputName': name,
'S3Input': {
'S3Uri': input_s3_uri,
'LocalPath': output_path,
'S3DataType': 'S3Prefix',
'S3InputMode': 'File'
}
}
def get_file_output(name: str, local_path: str, ouput_s3_uri: str):
""" Returns output file configuration
Modify for different output method """
return {
'OutputName': name,
'S3Output': {
'S3Uri': ouput_s3_uri,
'LocalPath': local_path,
'S3UploadMode': 'EndOfJob'
}
}
def get_app_spec(image_uri: str, container_arguments: Optional[str], entrypoint: Optional[str]):
app_spec = {
'ImageUri': image_uri
}
if container_arguments is not None:
app_spec['ContainerArguments'] = container_arguments
if entrypoint is not None:
# Similar to ScriptProcessor in sagemaker SDK:
# Run a custome script within the container
app_spec['ContainerEntrypoint'] = ['python', entrypoint]
return app_spec
def lambda_handler(event, context):
# (1) Get inputs
input_uri = event['S3Input']
ouput_uri = event['S3Output']
image_uri = event['ImageUri']
script_uri = event.get('S3Script', None) # Optional: S3 path to custom script
# Get execution environment
role = event['RoleArn']
instance_type = event['InstanceType']
volume_size = event['VolumeSizeInGB']
max_runtime = event.get('MaxRuntimeInSeconds', 3600) # Default: 1h
container_arguments = event.get('ContainerArguments', None) # Optional: Arguments to pass to the container
entrypoint = None # Entrypoint to the container, will be set automatically later
job_name = get_unique_job_name('sm-processing-job') # (2)
#
# (3) Specify inputs / Outputs
#
inputs = [
get_file_input('data', input_uri, '/opt/ml/processing/input')
]
if script_uri is not None:
# Add custome script to the container (similar to ScriptProcessor)
inputs.append(get_file_input('script', script_uri, '/opt/ml/processing/code'))
# Make script new entrypoint for the container
filename = os.path.basename(script_uri)
entrypoint = f'/opt/ml/processing/code/{filename}'
outputs = [
get_file_output('output_data', '/opt/ml/processing/output', ouput_uri)
]
#
# Define execution environment
#
app_spec = get_app_spec(image_uri, container_arguments, entrypoint)
cluster_config = {
'InstanceCount': 1,
'InstanceType': instance_type,
'VolumeSizeInGB': volume_size
}
#
# (4) Create processing job and return job ARN
#
sm.create_processing_job(
ProcessingInputs=inputs,
ProcessingOutputConfig={
'Outputs': outputs
},
ProcessingJobName=job_name,
ProcessingResources={
'ClusterConfig': cluster_config
},
StoppingCondition={
'MaxRuntimeInSeconds': max_runtime
},
AppSpecification=app_spec,
RoleArn=role
)
return {
'ProcessingJobName': job_name
}
The main steps in the code above are:
- First we extract the input parameters for the Lambda function, which are pretty much the same ones as for the
Processorclass in the SDK - A unique name for the job is generated based on
sm-processing-job-and the current timestamp - We add the inputs and outputs to the processing job. If you specified a custom script as the entry point, it is added as an input as well, so that SageMaker copies it into the container.
- Finally we create a SageMaker Processing job through the boto3 API.
Lambda Function: Monitor SageMaker Processing Job Status
The second lambda function is checking the process status based on the job name and returns it back to the Step Function:
import boto3
sm = boto3.client('sagemaker')
def lambda_handler(event, context):
job_name = event['ProcessingJobName']
response = sm.describe_processing_job(
ProcessingJobName=job_name
)
job_status = response["ProcessingJobStatus"]
print(response)
return {
'ProcessingJobName': job_name,
'ProcessingJobStatus': job_status
}
The steps are:
- We get the job name as an input from the previous Lambda
- We perform a boto3 API call to get the current job status and return it from the Lambda
Putting it all together: StepFunction Workflow
Now that we have all the building blocks, let’s put everything together. As outlined in the beginning, the steps for running a processing job are:
- StartProcessingJob: Call the first Lambda function to start our processing job
- Wait: Wait for some time (in this case 30s, but it depends largely on your use-case and the expected runtime of your job).
- GetJobStatus: Get the current status of the processing job
- IsDone?: Is the processing job still running, did it succeed or fail?
In Amazon State Language we can define the workflow as follows. Here I use one of the SageMaker Scikit-Learn containers, together with an example script I uploaded to S3. So the behavior will be similar to SKLearnProcessor. Note, that the code contains some place holders that will be replaced by the CloudFormation template shown below:
{
"Comment": "An example how to run SageMaker Processing Jobs within a StepFunction",
"StartAt": "StartProcessingJob",
"States": {
"StartProcessingJob": {
"Type": "Task",
"Resource": "${StartJobLambda.Arn}",
"Parameters": {
"S3Input": "${S3Input}",
"S3Output": "${S3Output}",
"ImageUri": "141502667606.dkr.ecr.eu-west-1.amazonaws.com/sagemaker-scikit-learn:0.20.0-cpu-py3",
"S3Script": "${S3Script}",
"RoleArn": "${LambdaRole.Arn}",
"InstanceType": "ml.t3.medium",
"VolumeSizeInGB": 20
},
"Next": "Wait"
},
"Wait": {
"Type": "Wait",
"Seconds": 30,
"Next": "GetJobStatus"
},
"GetJobStatus": {
"Type": "Task",
"Resource": "${GetStatusLambda.Arn}",
"Parameters": {
"ProcessingJobName.$": "$.ProcessingJobName"
},
"Next": "IsDone?"
},
"IsDone?": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.ProcessingJobStatus",
"StringEquals": "Completed",
"Next": "Success"
},
{
"Variable": "$.ProcessingJobStatus",
"StringEquals": "Failed",
"Next": "Failure"
}
],
"Default": "Wait"
},
"Success": {
"Type": "Pass",
"End": true
},
"Failure": {
"Type": "Fail"
}
}
}
I created a CloudFormation template to set everything up for you. To set it up, go to the CloudFormation service in the AWS Console and upload the cloudformation.yml to create a new stack. You are then asked for the S3 path to you input data (S3Input), the output path (S3Output) and the location of the script you want to run (S3Script). You could also use the AWS Console to setup everything manually. What the template will set up for you is:
- IAM roles for running the Lambda Functions and the StepFunction Workflow
- A Lambda function
start_processing_job, with the code to start a SageMaker Processing job from above - A Lambda function
get_processing_job_status, with the code for checking the Processing Job status - A StepFunction Workflow with the definition we see below
Summary
In the post above, I showed you how you can run Processing jobs from within a Step Function workflow. We implemented two Lambdas, which start the Processing job and monitor its status. The code can be found on GitHub and should be easy to adapt for your use-case. If you have questions or comments, don’t hesitate to ask in the comments below.
Like the post? Share it!

Simon Löw
Machine Learning Engineer - Freelancer
I'm an ML Engineer freelancer focusing on building end-to-end machine learning solutions, including the MLOps infrastructure and data pipelines.
I've worked with various startups and scale-ups, including Klarna and Depict, building automated ML platforms, credit risk models, recommender systems, and the surrounding cloud infrastructure.
On this blog, I'm sharing my experience building real-world end-to-end ML solutions.
Follow me on LinkedIn